Highlights:
- Genealogists can quickly generate a cleaner copy of an old newspaper article (not a perfect final draft) from a messy OCR text dump.
- A carefully crafted PROMPT found and fixed 49 out of 54 errors in an newspaper OCR article text.
- NO HALLUCINATIONS were introduced into the response.
- The AI was limited to processing the text it was given.
I love newspaper archives. I love them so much that I keep paid subscriptions to at least three major vendors (and perhaps others I’ve forgotten I’m still paying for), not to mention my love for Chronicling American, DigitalNC, and other free state and national newspaper archives.
But as researchers know, one of the most challenging aspects of newspaper research is finding the articles you want. This difficulty is largely the result of the imperfect quality of the text that vendors and archives generated from image scans of newspapers. It’s hard work, and I give them credit for making so many old newspapers text-searchable at reasonable prices. And it is beyond the scope of this article to cover the dark arts of newspaper archive searching.
This article assumes that you have successfully found an old newspaper article, but you discover that the raw OCR text of the article is error-ridden. If you need a clean copy of the text as it appeared originally in the newspaper, you have a couple of choices: (1) you can transcribe, dictate, or re-type the whole article from scratch, or (2) you can copy-and-paste the OCR text that is made available and you can manually clean-up that raw text dump. Neither of these tasks are quick and easy.
Now, artificial intelligence can quickly help you generate a much cleaner version of the OCR raw text dump. The result will not be a pristine version of the original article; it will not be a final draft–you will still need to verify and proofread the AI-cleaned text. But it will help. My experience in this experiment was that a carefully crafted PROMPT found and fixed 49 out of 54 errors in an newspaper OCR article text.
Earlier this week, I wrote about my discovery that ChatGPT can create, read, and interpret family trees (GEDCOM files) and how to use ChatGPT to glean family history information from obituaries, birth, wedding, and marriage announcements, and the usefulness of ChatGPT in analyzing complex genealogical relationships found in a genealogically rich and dense newspaper article. In the second article, I used as an example a newspaper wedding announcement from of a distant aunt. The wedding announcement was about 430 words, of which more than one-in-eight words were mangled by the original OCR process.
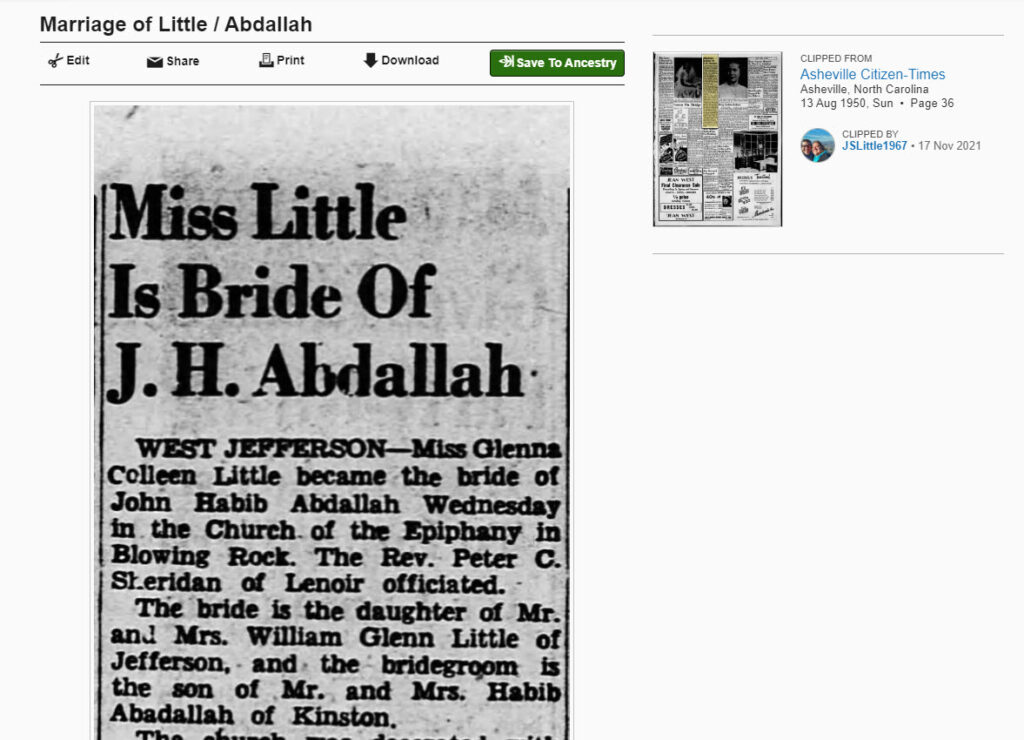
The raw text dump from the original OCR scan can be seen below. If you are a quick typist, or if you enjoy correcting and proofreading OCR text, then the errors in this text is not a problem. But if you would like to quickly get to a much cleaner copy, then AI can help.

This is about the seventh or eighth PROMPT I tried, iterating through a process of trial-and-error, improving (usually) with each attempt. And by asking ChatGPT (Model GPT-4) how I could craft a prompt that would prioritize fidelity to the original text.
The goal is to have the AI act like a glorified spell checker, squelching any creativity, and preventing hallucinations, while quickly cleaning-up the original text. (One standard practice should be to start a new AI chat session with each new article; see the previous post for more information.)
So, here is my most recent PROMPT to clean-up OCR text while prioritizing fidelity to the meaning of the original text as having the highest importance.
PROMPT: Normalize the following transcribed historical document by correcting spelling errors, expanding abbreviations, standardizing capitalization and punctuation, and adjusting formatting for improved readability, while preserving the original meaning and context. Provide clear documentation of any changes made during the normalization process:
Results were good. Very good. In the Diffchecker comparisons below, you can see how good. What follows are three sets of comparisons: (1) the original, pristine text of the wedding announcement as it would have been seen and read in 1950 verses the OCR raw text dump; (2) the OCR raw text dump given to ChatGPT verses the ChatGPT-cleaned output; and (3) the pristine 1950 text verses the AI-cleaned text.
In these comparisons, a paragraph which contains differences is highlighted in light-red (original text) or light-green (comparison text). Individual words that are different are highlighted in dark red (in the original text) and dark green (in the comparison text).
In this first comparison, you can see how the vendor-provided OCR raw text dump compares to the manually-cleaned text of the original article. The red-highlighted text on the left contains the article as it was printed in the newspaper in 1950. The green-highlighted text on the right shows that there were transcription errors in all eight of eight paragraphs, over 50 errors in all, many so significant as to make the words and sentences nearly meaningless. Consider this set the “Before” in a before-and-after comparison:

This second set of comparisons shows the how many “errors” in the OCR text dump that ChatGPT found and fixed. The red-highlighted text on the left is the OCR text dump; the green-highlighted text on the right is the AI-cleaned copy. Note that ChatGPT found over 50 errors (dark red and green highlighted words) in all eight paragraphs (explaining why all the paragraphs are highlighted in light-red and light-green).

This third and final set of comparisons show the pristine original article as it would have been seen and read in 1950 beside the AI-cleaned version. ChatGPT had found and fixed 49 “errors” in the original OCR text dump. Consider this set the “After” in a before-and-after comparison. Note that there only a very few differences between the article as it appeared in 1950 and the AI-cleaned copy. And if we look closely at those few remaining differences, something very interesting is revealed.

There were only five differences between the pristine original text and the AI-cleaned text:
- “Glenna” verses “Glenn”: The bride’s name was Glenna Little. The OCR text dump dropped the final letter, the letter “a” in Glenna, mistaken her name as “Glenn Little.” ChatGPT choose to leave the name unchanged from the input it was given, “Glenn Little.” I wonder if it considered that a bride’s name might have been “Glenna,” but rejected that choice. Interesting. But I think it made the right call.
- “Wednesday” verses “on Wednesday”: ChatGPT choose to insert a preposition. Significant?
- [given in] “marriage by her father” verses [given in] “marriage”: ChatGPT dropped by a whole prepositional phrase “by her father.” I haven’t a clue why that would have happened.
- “Chantilly” [lace] verses “chantilly” [lace]: ChatGPT choose to make lowercase the word “chantilly”. Again, I don’t know why. Wikipedia chooses to make the word always capitalized, even when used in the middle of a sentence, because, I presume, the word is the name of a city in France.
- “chapel length” [veil] verses “chapel–length” [veil]: ChatGPT choose to hyphenate “chapel-length”.
How significant and meaningful do you judge these five remaining differences? No hallucinations were introduced into the text. More than 90% of the mangled text generated by the OCR were found and corrected; that is, 49 out of 55 differences between the pristine original text and the OCR text dump were found and corrected. And remember: There is nothing sacred about the OCR text dump.
Next step: Process that clean text: You can use this clean OCR text with the PROMPT I shared earlier to glean genealogical information from a newspaper article, creating family tree (GEDCOM) files and tables of relationship with the information highlighted that was used to make that determination.
To re-state an important caveat:
- This prompt creates a second draft, not a final draft. Just as you would not uncritically use the raw OCR text dump, this second draft requires verification and proofreading.
Artificial intelligence, specifically ChatGPT, has potential to be a valuable tool for genealogists and researchers in their quest for a cleaner, more accurate version of OCR-generated newspaper articles. While not perfect, AI technology managed to find and fix a significant number of errors in the OCR text, saving time and effort in the process.
However, it is crucial to remember that the AI-generated output serves as a second draft and not a final copy. Researchers must still verify and proofread the text to ensure complete accuracy. As AI technology continues to advance, we can expect even better performance in cleaning up OCR text, further aiding genealogists and researchers in their work.
In the meantime, the use of AI like ChatGPT offers a promising solution to one of the challenges faced in genealogical research, helping to bring the past closer to the present with greater clarity and understanding.
Imagine if newspaper archive holder and vendors AI-processed their existing OCR texts. The usefulness of your search results will increase significantly. They wouldn’t have to replace their existing OCR texts. They could supplement their current text with the AI-cleaned text. I suspect their users would greatly value that added usefulness.

POST SCRIPT: A final note to vendors and archives: A wish list item from your most ardent supporters: even if you can’t re-scan your newspapers, please consider AI-processing the raw OCR text you already have.
POST POST SCRIPT: If you find this post helpful, please share it with a friend. Or, if you just want to share the prompt, a nod, hat-tip, or acknowledgment is appreciated.