How to Extract Information from Text Sources Using Artificial Intelligence
Three examples: obituary, wedding announcement, newspaper article
After my discoveries last week that ChatGPT (model GPT-4) can: (1) create, read, and correctly interpret GEDCOM files, (2) create narrative reports based only on GEDCOM data, (3) match narrative style to location and setting of text, and (4) generate inline superscript reference note numbers and provide their corresponding reference notes or source citations as endnotes from GEDCOM sources, I was interested to find out what other sources from which ChatGPT could extract genealogical information.
So, while we wait for visual record processing, which will turn a folder of birth, marriage, and death certificates into sourced family trees, I’ve been focused on learning how to use AI tools to wring every drop of genealogical information from text sources, such as obituaries, engagement and wedding announcements, and newspaper articles, and having this sourced information collected in orderly and useful formats, such as spreadsheets (CSV files), family trees (GEDCOM files), JSON files, and other useful formats.
Helping people find the information they need in texts has been a passion for 30 years. I trained to do this work during a first career in information technology at law, university, and archival libraries. My last job in that field was as a digital archivist for the Library of Virginia helping local libraries preserve, archive, catalog, and publish online their photograph collections. And before that work, my graduate studies were in applied linguists; while my classmates were studying to become English teachers, my interest was computation linguistics and natural language processing. A three-decade interest in regular expressions (fancy search-and-replace programming) has been its own reward.
But now, those advanced skills are not needed to use ChatGPT to extract genealogical useful information from obituaries, birth/engagement/wedding announcements, or newspaper articles. Now, everyone, with a thoughtful PROMPT expressed in plain, natural language, can quickly gather and harvest sourced information into useful collections. This post steps the reader through three examples of using ChatGPT to extract and glean information from three texts (an obituary, an engagement/wedding announcement, and a genealogically rich newspaper article); save the information in appropriately useful formats; and create and store source citations with the information.
The first example is an obituary, often a genealogically rich text. This is the process I used to glean information (people, relationships, events, places) from the obituary and to store the information, complete with source citation, in various formats. The obituary was written by a friend and published in the Washington Post after the death on 2 March 2023 of Theodore S. Kanamine, the U.S. Army’s first Japanese-American active duty general. Some AI’s are capable of extracting and summarizing information given only a URL (web address), but for this example, I will use ChatGPT (model GPT-4), which currently (at least for the moment) allows only text input. This means that I will be copying-and-pasting the text of the obituary into the chat dialog. But the AI must first be given instructions, called a PROMPT, natural language directions that you wish the AI to follow.
Here is the first PROMPT I used:
PROMPT: Assume the role of an expert, professional genealogist. Consider the genealogically relevant information that might appear in an obituary. Below is the text of an obituary. I would like to know about the stated relationships between people in the text. When you can with certainty, state the relationship between two people in the article. Present the information in two formats. First, In a markdown table use the form PERSON ONE : PERSON TWO : RELATIONSHIP : INFORMATION. (Where INFORMATION is the quoted text in the article describing the relationship between the two people.) Second, create a GEDCOM file for the named people in the text; include source information in the GEDCOM file.Below the PROMPT, I pasted the text from the obituary. Here is first table of information that ChatGPT quickly returned:
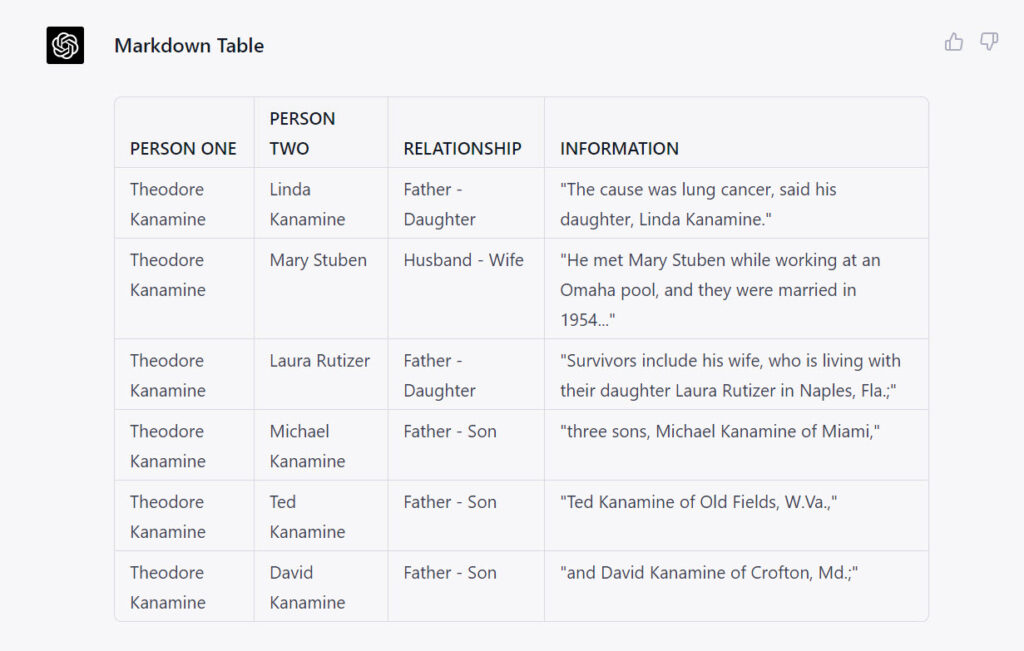
Note that ChatGPT included with this PROMPT a quotation which it had used to determine a relationship; this allows the researcher to verify the AI’s claim.
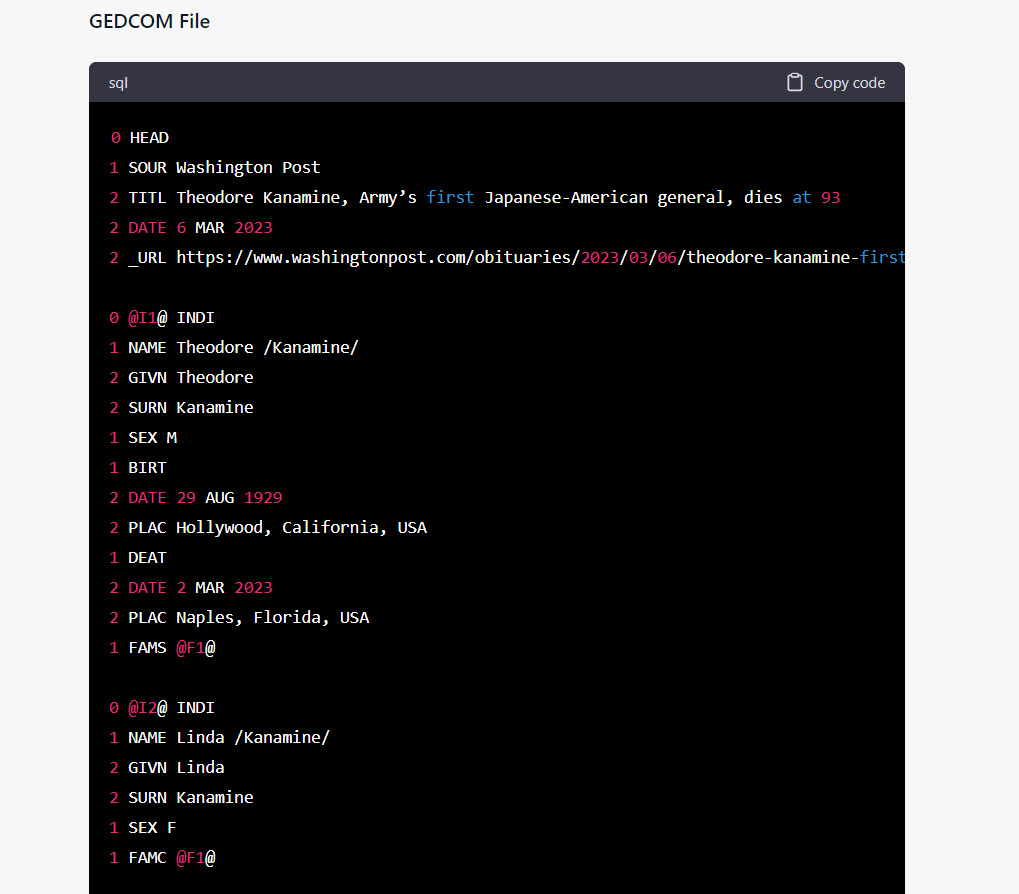
ChatGPT was also able to quickly generate a working, sourced family tree (GEDCOM file) from the obituary, as seen here. Note the source information is included in the file. By clicking the “Copy code” button at the upper right corner of the dialog, the text of the GEDCOM can quickly be copied-and-pasted into a text editor, saved with the *.ged extension, and opened or imported to any genealogy application such as RootsMagic or Family Tree Maker.
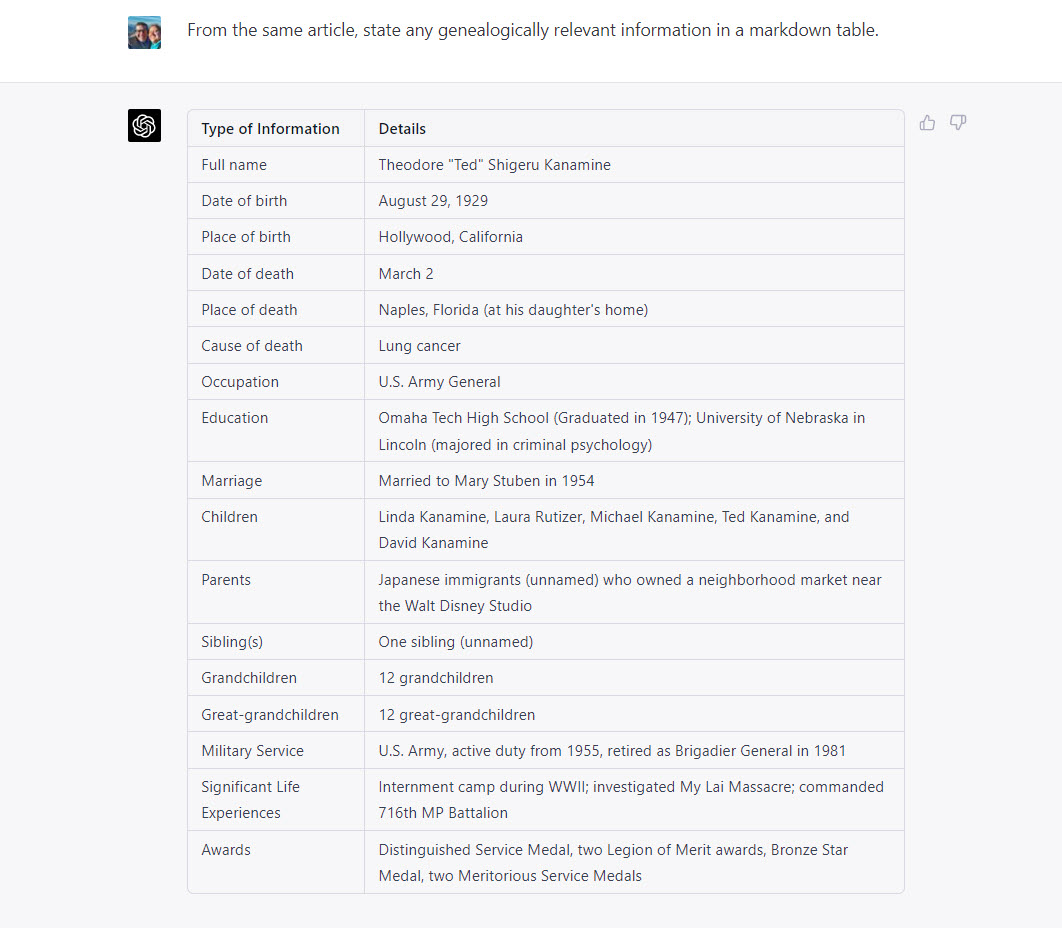
Family relationships are not the only information included in obituaries. Often obituaries will contain other genealogically useful information. So I prompted ChatGPT to glean other information, which produced this table:
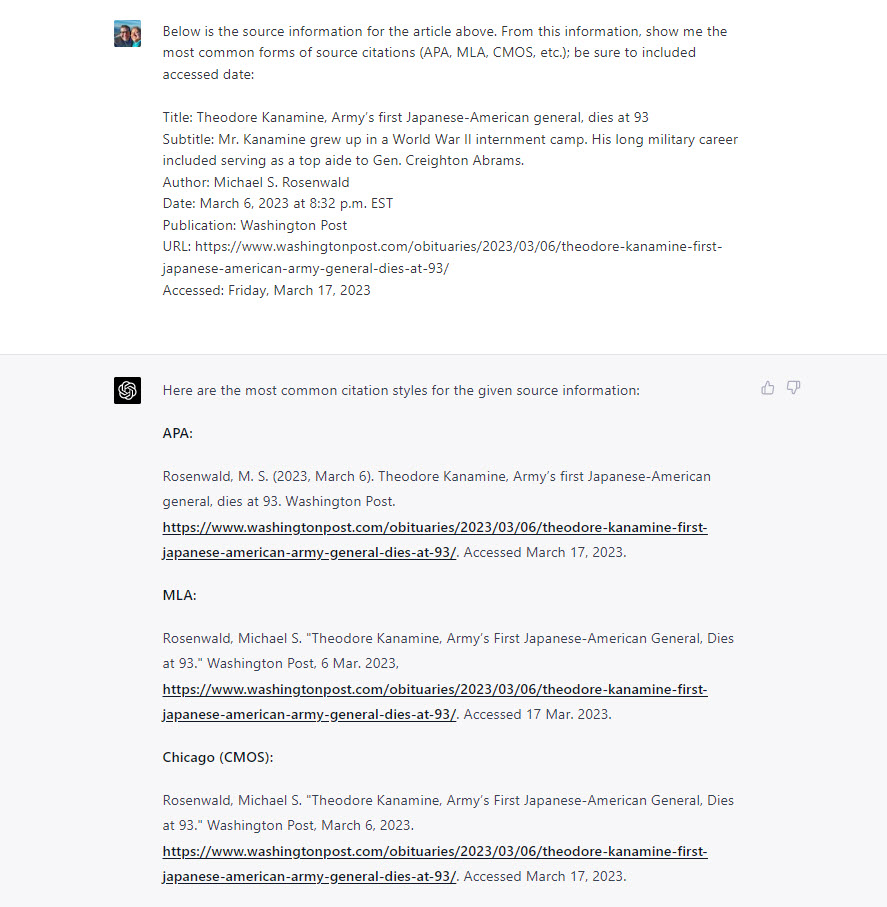
Also, ChatGPT was helpful in creating a citation. At first, I forgot to include the Date Accessed information. And then, even when I did include an Accessed date, ChatGPT did NOT initially include it in its citations, but, when on my third attempt, I explicitly instructed ChatGPT to include the access date, it did:
PRO TIP: In genealogy AI work, start new chat sessions or conversations before beginning to work with a new text or article. Chatbots work by re-processing your earlier conversation utterances. You can contaminate later parts of a conversation with earlier prompts and input.
Steve Little
Obituaries are not the only source of genealogical information that can be found in newspapers. Often, birth, engagement, and wedding announcements are rich with information. ChatGPT can quickly present information found in those type of texts. The next example involves a longer wedding announcement. Start new chat sessions or conversations before beginning to work with a new text or article. Chatbots work by re-processing your earlier conversation utterances. You can contaminate later parts of a conversation with earlier prompts and input.
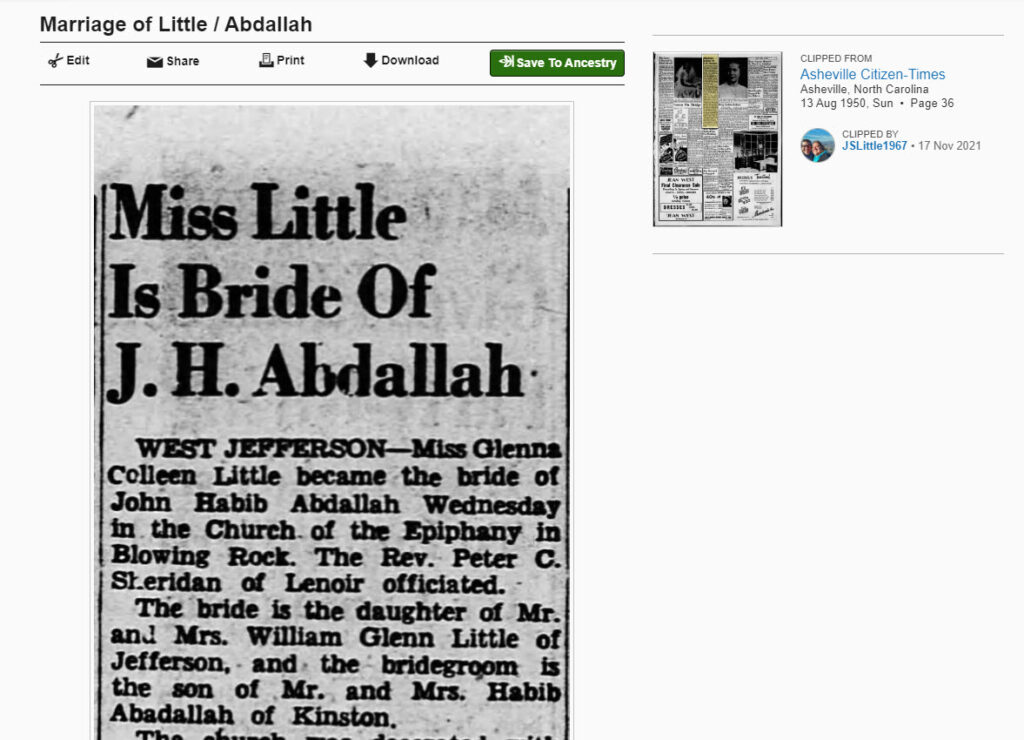
After paying attention to start a new chat session my prompt for the wedding announce was almost identical to the prompt for the obituary, but slightly re-worded. The input text for the announcement was provided by the newspaper archive vendor; most vendors provide a link to the OCR’d text that makes the articles searchable.
PROMPT: Assume the role of an expert, professional genealogist. Consider the genealogically relevant information that might appear in a wedding announcement. Below is the OCR text (correct for spelling) of an announcement. I would like to know about the stated relationships between people in the text. When you can with certainty, state the relationship between two people in the article. Present the information in two formats. First, In a markdown table use the form PERSON ONE : PERSON TWO : RELATIONSHIP : INFORMATION. (Where INFORMATION is the quoted text in the article describing the relationship between the two people.) Second, create a GEDCOM file for the named people in the text; include source information in the GEDCOM file.Again, ChatGPT quickly responded with a table of relationships between people:
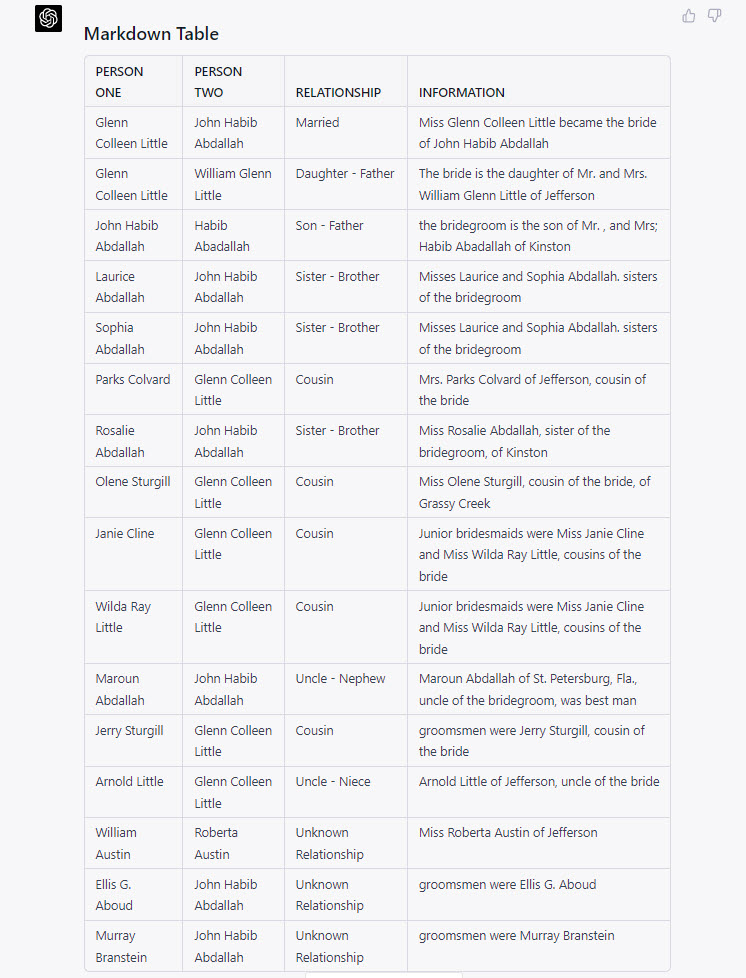
This prompt also produced a functional family tree (GEDCOM) file, but since we have already seen an example of that, I asked ChatGPT to render the information in the markdown table into a format that could quickly be imported to a spreadsheet (such as Excel or Google Sheets) or a database (such as Airtable or MySQL), a CSV or “comma separated value” file.
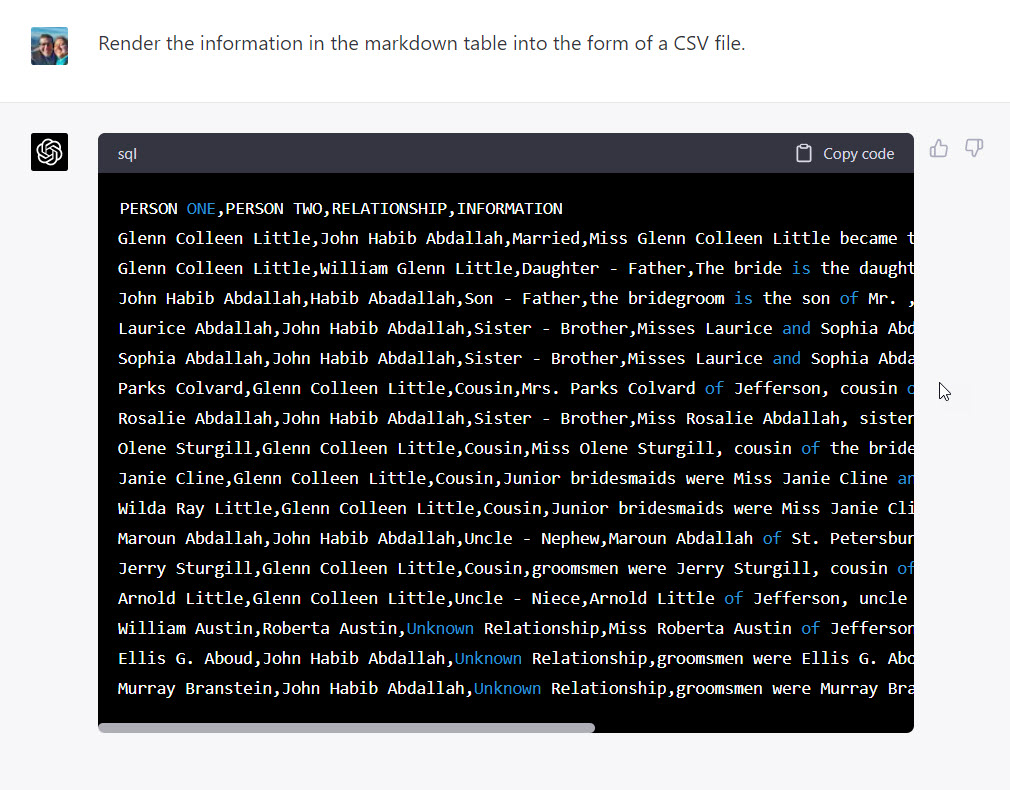
Saved with a *.csv extension such as “LITTLE-Abdallah wedding.csv”, the information could quickly be imported into many other applications.
Our next example uses a much longer, more complex piece of writing.
[LANGUAGE NOTE: This section includes discussions and language related to the relationships between the descendants of enslaved people and their enslavers, which some readers may find sensitive. Language models like ChatGPT are trained on large amounts of text that may contain outdated or offensive language. Engaging with appropriate communities for advice on respectful language usage is recommended.]
Our final example involves a genealogically rich newspaper article. Some years ago, some cousins discovered a shared ancestry. As descendants of enslaved people and their enslavers, DNA evidence and documentary sources revealed their intertwined heritage. A local genealogist and writer, Janet Pittard, wrote an article describing how these descendants of slaves and slave owners acknowledged their complex past to cultivate new bonds. I am related to all these folks. But the first time I read the article, it was a bit of a challenge to keep the relationships straight in my mind.
Helping to make clear dense genealogical text is a task with which AI will be useful. Two prompts were able to create several tables and charts showing the relationships and events in the article, making them easy to see and understand.

At just under 2000 words, the article was short enough for today’s input limit. My initial prompt was similar to the one I used with the obituary and the wedding announcement.
PROMPT: Assume the role of an expert, professional genealogist. Below is a newspaper article about several families. I would like to know about the stated relationships between people in the article. When you can with certainty, state the relationship between two people in the article. In a markdown table use the form PERSON ONE : PERSON TWO : RELATIONSHIP : INFORMATION. (Where INFORMATION is the quoted text in the article describing the relationship between the two people.)This screenshot of the prompt shows how I request the relationship results be displayed in a markdown table, and show the beginning of the article in the chat dialog.
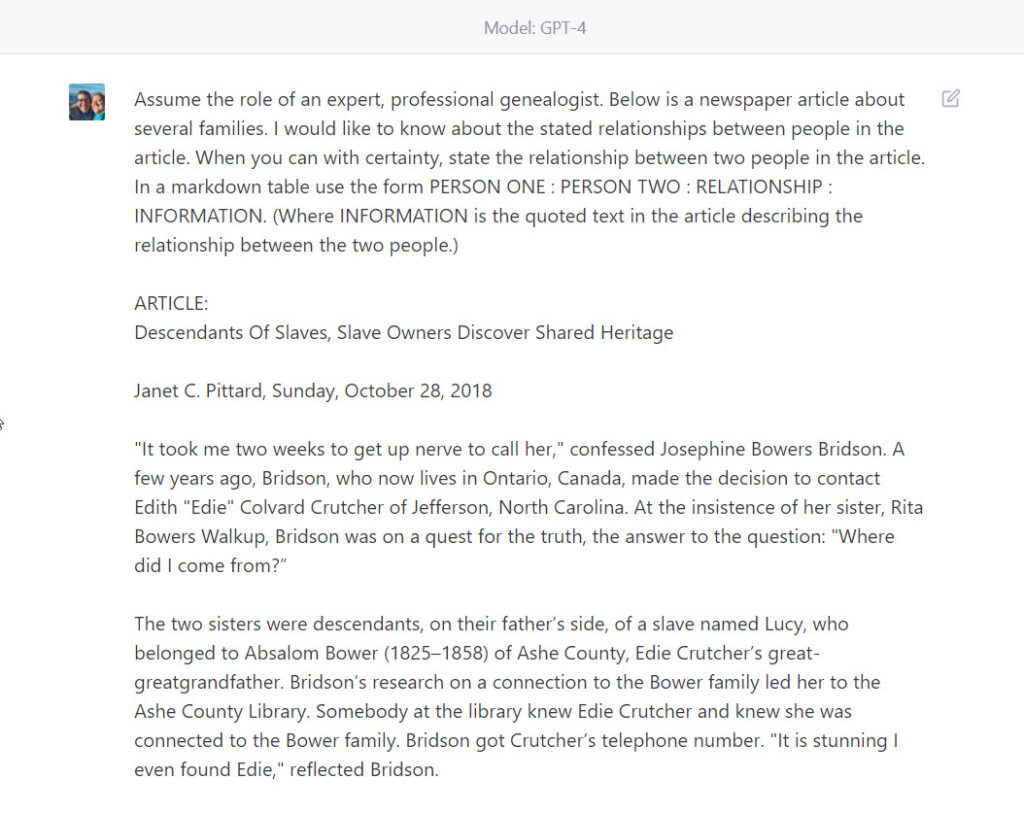
ChatGPT (model GPT-4) responded with this markdown table (screenshot image). Again, the results could also have been rendered as a family tree file (GEDCOM), spreadsheet or database file (CSV), or other text formats, such as a JSON for further computational processing, or as a narrative, abbreviated summary of the relationships.
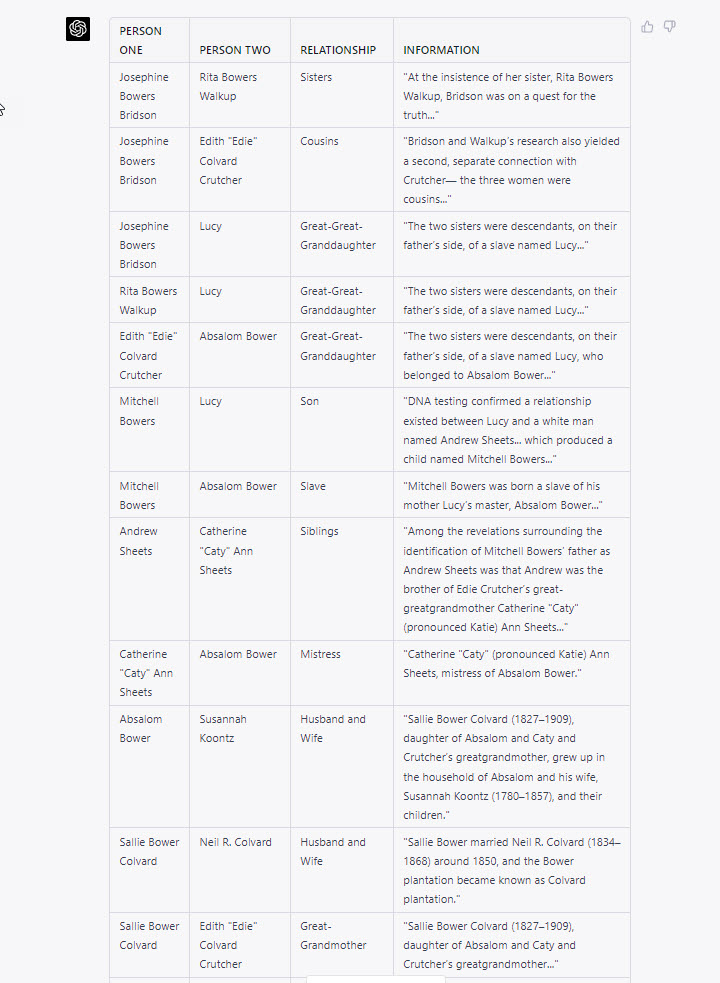
This final prompt was new. I was curious if ChatGPT could extract a chronological list of events in the article, sort the list from oldest event to newest event, and include the people active in the event, the location of the event, and the quoted text from the article mentioning the event. ChatGPT was mostly successful. The one error I noticed was misunderstanding a lifespan as the date range of an event; that is, on the first event row, Absalom Bower’s birth and death dates, (1825-1858), were, I think, incorrectly recorded as the dates Lucy was enslaved by Bower. The meaning and significance of this error may be worthy of further testing and consideration.
The prompt, despite that error, still performed well, generating a table of five other events mentioned in the article. ChatGPT was also successful in correctly sorting the events chronologically, from oldest to newest. I was somewhat surprised by this success, as a noted weakness with basic math has been observed in earlier GPT models.
Here is the prompt I crafted to generate the table of events from the genealogically rich text:
PROMPT: Create a markdown table of events in the article; use the form:
EVENT | PEOPLE | LOCATION | DATE | INFORMATION
(Where INFORMATION is the quoted text from the article describing the noted event.)
(Sort the table chronologically by date, from oldest to newest.)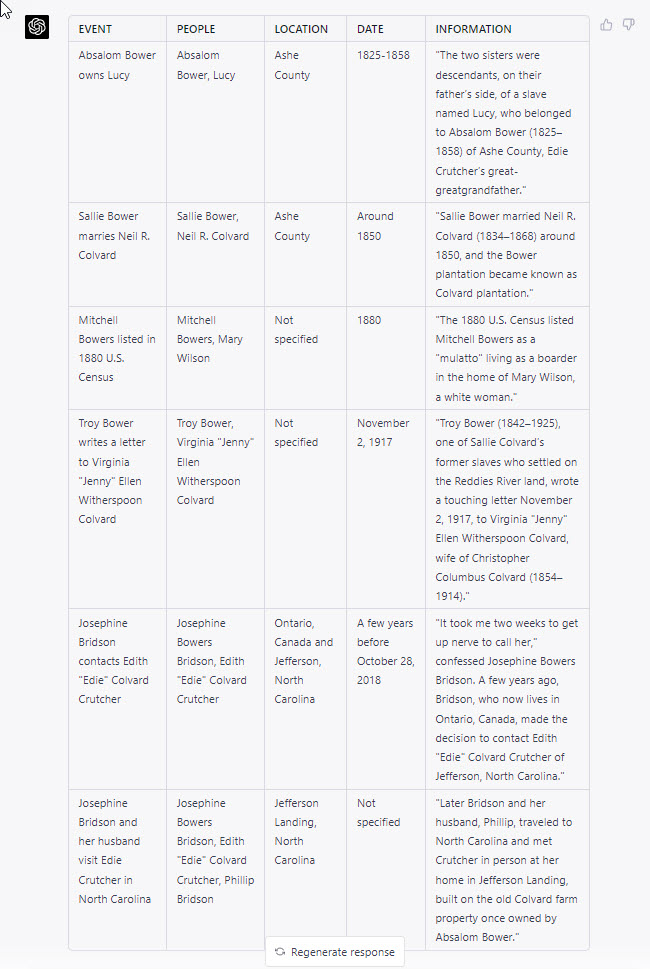
In conclusion, artificial intelligence, particularly ChatGPT (model GPT-4), offers an efficient and innovative way to extract genealogical information from various text sources such as obituaries, wedding announcements, and newspaper articles. By using carefully crafted prompts, users can have the AI interpret and summarize relationships, events, and other relevant information in a variety of formats, including markdown tables, GEDCOM files, and CSV files. This allows researchers to quickly gather and store sourced information for further analysis and application.
While ChatGPT has made it possible for users without advanced computational linguistics skills to perform these tasks, it is essential to approach the process thoughtfully, carefully crafting prompts and verifying the AI’s outputs. Additionally, starting new chat sessions or conversations for each new text source is vital to avoid contamination of the AI’s processing.
As AI continues to advance, we can expect further improvements in its capabilities, making it even more valuable for genealogical research and other fields that require extracting relevant information from large volumes of text.
This just blows my 79 year old mind! It seems unbelievable.
Hi, Robert! I’m glad to read that you seem to have found the article interesting. Have you had a chance yet to work with ChatGPT? The site is often busy, but free accounts are available at https://chat.openai.com/chat. If I can help with anything, or you would like to share your experience, please do write again. Best wishes, Steve