- Go directly to the step-by-step walk-through.
- This detailed how-to is a follow-up to the use case announcement from March 22, 2023 titled “AI Genealogy Use Case: Cleaning-up OCR Text“
- This preliminary step prepares the AI Genealogist for other valid use cases today; cleaning your OCR text help eliminate “garbage in, garbage out” information processing.
Introduction: Cleaning-up incorrect and messily scanned text from newspapers, books, and other archive materials is often a first step in AI Genealogy, before running AI-powered tasks such as name, relationship, date, place, and event analysis on a text (birth or wedding announcement, obituary, newspaper article, or book chapter).
- Artificial intelligence can be applied to quickly improve the quality of machine generated text from scanned newspapers, books, microfilm, records, and other archived materials.
- When records are originally scanned, they are in an image format which cannot be searched by keyword or name; “optical character recognition” (OCR) is a computer process which attempts to determine the text in an image. Most traditional OCR software attempted text extraction character-by-character, without regard to a character’s place in a word, or a word’s place in a sentence. So OCR software gave no consideration whether “13” or “B” made contextual sense while rendering an image to text.
- Large language models, the type of artificial intelligence powering systems such as OpenAI’s ChatGPT and GPT-4, can determine which is statistically more likely:
- “13ob Smith” or “Bob Smith”
- “1B4 South Main Street” or “1134 South Main Street”
- Currently many OCR archives have an 80% to 90% accuracy rate, which is worse than it sounds. That doesn’t mean that 1 out of 5 words is incorrect, but rather that 1 out of 5 characters is incorrect, which means that every 5th letter could be incorrect, meaning that every word with 5 or more letters may be spelled incorrectly.
- This helps explains why newspaper archive searches are notoriously difficult.
- Cleaning-up incorrect and messily scanned OCR text from newspapers, books, and other archive materials is often a first step in AI Genealogy, before running AI-powered tasks such as name, relationship, date, place, and event analysis on a text (birth or wedding announcement, obituary, newspaper article, or book chapter).
Objectives:
- Correct to standard English raw and/or bad OCR text, attending to spelling, grammar, punctuation, and structure, prioritizing the meaning and context of the original source.
Requirements:
- OCR text to process. In this demonstration, an obituary from Chronicling America, a venture between the Library of Congress and the National Endowment for the Humanities, is used as an example: “Deaths in Virginia: Charles F. Fravel,” Richmond Times-Dispatch. [volume] (Richmond, Va.), 15 March 1922. Chronicling America: Historic American Newspapers. Lib. of Congress. https://chroniclingamerica.loc.gov/lccn/sn83045389/1922-03-15/ed-1/seq-11/ < accessed: Sat 15 Apr 2023 >.
- Access to an artificial intelligence. In this demonstration, ChatGPT-Plus (Model: GPT-4, version March 23, 2023) was used on Sat 15 Apr 2023.
Caveats for the Careful: Misunderstood use; limited knowledge; limited size
- As of spring 2023, most large language models like ChatGPT do not have live internet access; GPT-4 was trained on data as current only as of September 2021.
- Even so, large language models do not do fact-based research, and so should NOT be relied upon to return accurate information, even pre-dating September 2021; large language models work by returning the statistically most likely word in a phrase (for more information, see Stephen Wolfram’s “What Is ChatGPT Doing … and Why Does It Work?“
- OpenAI includes this caveat with every ChatGPT response: “ChatGPT may produce inaccurate information about people, places, or facts.” In other words, to paraphrase my algebra teacher, while a blind squirrel may occasionally find an acorn, large language models are like well-trained blind squirrels that often find acorns but may occasionally return another kind of nut or something else vaguely resembling a nut.
- Because of this current unreliability, most of my AI-assisted genealogical tasks involve not research but information processing or data processing, that is, using the AI to work with the information I provide and only the information I provide. In the spring of 2023, the primary task of the AI genealogy for me is to constrain or limit through careful prompt engineering to clean, extract, transform, translate, or otherwise work with my information, not to find new information. Not yet.
- As of spring 2023, for most people and cases, the amount of information that can be processed is limited to approximately 1500 words of input and 1500 words of output. (Or, in the vendors’ jargon, 4k “total tokens,” more akin to 4000 syllables input and output combined, rather than words.
- Chatbots don’t have “memory” in the traditional sense that we think of either people or computers having either short-term or long-term memory. Chatbots simulate the memory to carry-on a conversation by re-digesting up to the past, roughly, 400 lines of your current conversation each time you click Submit. This means that you can inadvertently contaminate a response with an earlier utterance from you or the AI. For this reason, I frequently start a New Chat for each genealogical task.
How To: Methodology: Step-by-step to clean raw, bad OCR text with AI
- Find your OCR text. Newspaper and other archives usually provide access to the raw OCR text from their attempts to make records searchable. Chronicling American provides a “Text” link to access the raw OCR.
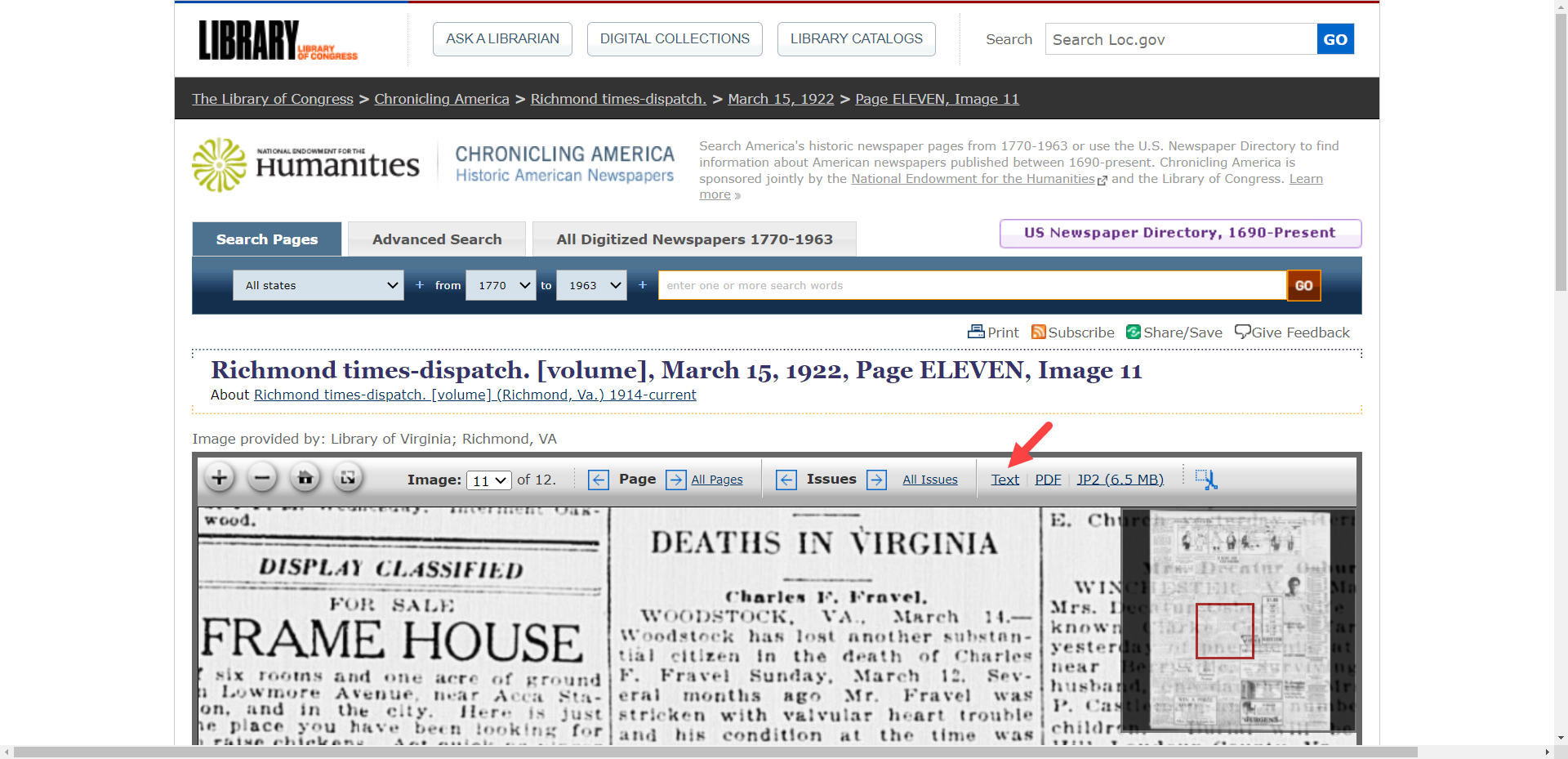
- Copy your OCR text. After clicking “Text” or “OCR Source,” vendors may link you to the text for a whole page or just the article in which you are interested; incongruent, disconnected, and separated “(continued on page XX) sections will have to been copied separately.
- Paste your OCR text. You may wish to consider saving the raw, messy OCR text to a text file for several reasons. Having quick access to the raw OCR text gives you options: to compare the “before” and “after” results; to experiment trying different prompts with one AI, say ChatGPT; or to compare how different AI’s such as Bing Chat, Claude, and ChatGPT perform comparatively with the same prompt and the same input OCR text.
- Inspect (and perhaps correct) your OCR text. Look at the original OCR text that the vendor’s traditional OCR application generated. It may be fairly good. Or it may be shockingly bad. In certain cases, it may be worthwhile to manually make a quick correction to the raw OCR. In this example, the original OCR mistranscribed the name of the principle FRAVEL as KRAVEL in the title and occasionally in the body of the story; by correcting just the name in the title, ChatGPT brought the other misspellings into alignment.

- Start a New Chat at ChatGPT. As explained in greater detail in the Caveats above, starting a new chat session with each genealogical task lessens the chance of contaminating a response with earlier utterances.
- Consider and craft your prompt. Your prompt instructs the AI. Our goal with this OCR correction task is to have the AI act as a glorified spell checker, without injecting information not contained in the original OCR text. Here are two prompts that I have used successfully for OCR clean-up:
- PROMPT: Normalize the following raw OCR text by correcting spelling errors, expanding abbreviations, standardizing capitalization and punctuation, and adjusting formatting for improved readability, while preserving the original meaning and context. Provide clear documentation of any changes made during the normalization process.
- PROMPT: Correct the following raw OCR to standard English; prioritize the fidelity to the original context, meaning, and style.
- I’ve found for obituaries that the second prompt returns better results, while the first prompt works better for longer newspaper articles.
- Enter your prompt and paste your OCR text. In your new ChatGPT dialogue, enter your prompt and paste your raw OCR text.
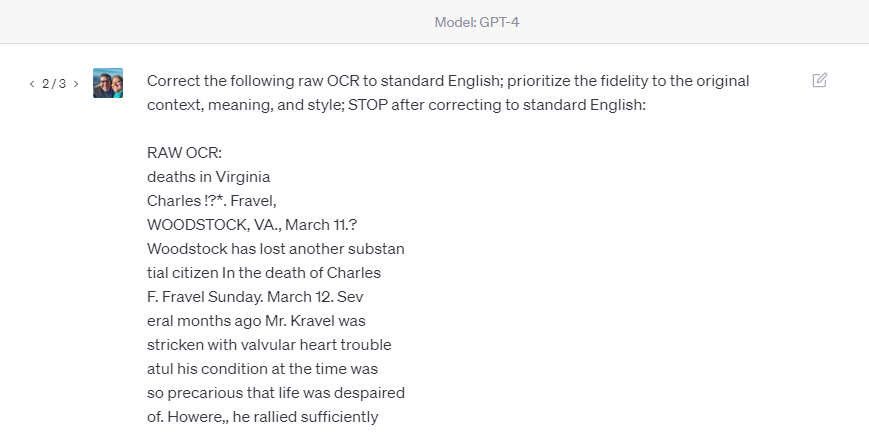
- Inspect ChatGPT’s response. Examine the results. Look for obvious errors, both new and uncorrected.
- Revise prompt if needed and re-run. Just as good writing means re-writing, so good prompt engineering means prompt re-writing. If there were new or remaining errors in your response, consider what modifications to your original prompt would eliminate those errors.
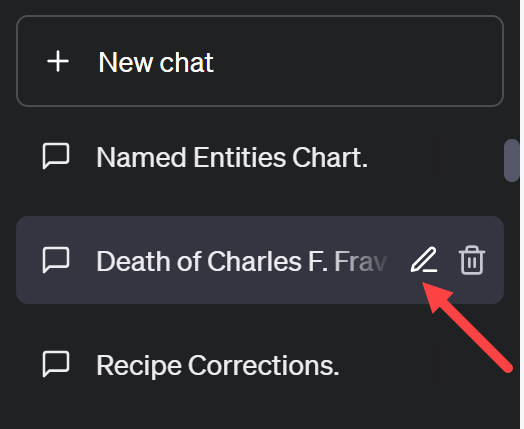
- Save your work. Save both your ChatGPT response by copying-and-pasting the text to a file on your computer. Save, too, the ChatGPT conversation by giving the dialogue a meaningful name; you can change the name of a ChatGPT conversation by hovering the mouse over the chat name in the left menu bar and clicking the pencil icon to edit the name; after changing the name, click the checkmark to save the new name. You now also have the option to download your complete ChatGPT history.
- Prepare for next steps. Rarely, if ever, is cleaning OCR text the end goal. Usually cleaning OCR text is a first step in a longer process of data extraction and information processing. You are now ready for those next steps.
Results and Analysis:

- Here are the “Before” and “After” results:
- BEFORE: deaths in Virginia Charles !?. Kravel, WOODSTOCK, VA., March 11.? Woodstock has lost another substan tial citizen In the death of Charles F. Kravel Sunday. March 12. Sev eral months ago Mr. Kravel was stricken with valvular heart trouble atul his condition at the time was so precarious that life was despaired of. Howere,, he rallied sufficiently to he out again and just a few days prior to his death was at his place of business. He was the son of the late James H. and Jone Kravel, or Woodstock, and was born September 20. 1K.9. He was married to Miss Ida B. JTottel. of I’ugh’s Run, on February 23. 1S*2. and two children survive, Dr. Hoy c. Kravel. of Richmond, and Tom H Fravel, of the Woodstock post office. Resides his two sons and his widow, he Is survived by one sister. M rs. Charles Raising, of Memphis, T? nn.
- AFTER: DEATHS IN VIRGINIA Charles F. Fravel, WOODSTOCK, VA., March 11 – Woodstock has lost another substantial citizen in the death of Charles F. Fravel on Sunday, March 12. Several months ago, Mr. Fravel was stricken with valvular heart trouble, and his condition at the time was so precarious that life was despaired of. However, he rallied sufficiently to be out again, and just a few days prior to his death, he was at his place of business. He was the son of the late James H. and Jane Fravel of Woodstock and was born on September 20, 1859. He was married to Miss Ida B. Hottel of Pugh’s Run on February 23, 1882, and two children survive: Dr. Roy C. Fravel of Richmond and Tom H. Fravel of the Woodstock post office. Besides his two sons and his widow, he is survived by one sister, Mrs. Charles Rising of Memphis, TN.
- Reasonable expectations: While surprisingly good, do not expect perfection; remember, large language models like ChatGPT and GPT-4 are playing the odds, picking the statistically most probable next word, so edge cases may result in errors.
Conclusions:
- ChatGPT can effectively be used today to clean raw, messy OCR text.
- This how-to example used a short, 150-word obituary. Currently, in April 2023, the input of most AI tools to which folks have ready access today is limited to about 1500 words input and 1500 words output, about three to six typed pages, depending on spacing. In April 2023, OpenAI announced 32k processing would be available soon, which would allow for about 50 pages of both input and output. In time, in hindsight, it will probably seem humorous that we were ever concerned about such tiny limits. Today’s limits are tomorrow’s breakthroughs.
Calls to Action:
- Try This Yourself: Find a birth or wedding announcement, obituary, or genealogically-rich newspaper article and give the OCR cleaning described on this page a try. Then, you are ready for…
- Today’s Next Steps: You can use text you cleaned today with the next use cases have been discovered and used successfully today: name, relationship, place, date, and entity recognition; then data extraction and information processing; text-to-GEDCOM; and narrative report creation.
- Archive owners and vendors should consider AI-processing their OCR text to improve the quality of their data; there is nothing sacred about the error-ridden raw OCR text that was created in decades past. Your users will experience greater value when your data is clean and yielding productive search results.
- Share your experiences, feedback, or questions in the comments section or on social media, especially the Facebook group “Genealogy and Artificial Intelligence.”
One thought on “AI Genealogy Use Case Guide: How to Clean Raw and Poor OCR Text”
Comments are closed.