Before we dive into this week’s terrible term, let’s revisit why Loathsome Jargon exists. It all started with a simple, searing dislike—mine—for jargon. Those convoluted, confidence-draining buzzwords that make perfectly good ideas sound like a secret society’s code language. AI, in particular, is a buzzing hive of these horrors. But here’s the truth: behind many off-putting terms lies a concept that can help you become a more effective researcher.
This column’s mission is simple: take these worrisome words, strip them of their mystique, and hand them back to you as tools for clarity, productivity, and maybe a grin along the way. Whether it’s a confusing acronym or a term that sounds like it belongs in a sci-fi novel, we’re going to break it down, demystify it, and show how it applies to your research.
Now, with that spirit of jargon-busting firmly in mind, let’s tackle this week’s Loathsome Jargon: “context window.”
This second column kicks off a mini-series dedicated to AI’s most glaring shortcomings—the ones that can trip up your research if left unaddressed. Today’s term, “context window,” offers a perfect starting point: it’s a concept that, when understood, can significantly improve the reliability of your AI-powered genealogy work.
What Is a Context Window?
Think of a context window as the AI’s short-term memory. It defines how much information the model can keep “in mind” at any one time—like a sticky note with a limited amount of space. Staying within this memory limit is critical because exceeding it can lead to hallucinations (AI errors) or dropped information, which can derail your research.
The context window encompasses everything the AI processes in a single session: uploaded files or documents, your current prompt, and—importantly—all previous exchanges in the conversation. As your interaction grows, older parts of the conversation may “fall out” of the context window, meaning the AI can no longer “remember” them. This limitation underscores why careful management of input and output is essential.
A Historical Illustration: Jefferson vs. Washington
In the first AI genealogy class I taught in the fall of 2023, we experimented with historical documents to see how well the AI handled different text lengths. We used the will of Thomas Jefferson—a concise, three-page document—as our exercise source. The AI managed it beautifully, keeping the entire text within its short-term memory. But when we considered using George Washington’s six-page will, we quickly realized it would exceed the model’s capacity at the time. The AI wouldn’t have been able to keep the full document “in mind,” increasing the likelihood of errors or omissions.
Fast forward to 2025, and context windows have expanded significantly. Modern models can handle much larger inputs, but today the principle remains: to get the best results, you must respect the model’s memory limits.
Practical Tips for Genealogists
- Know Your Model’s Limits: Different models have different context window sizes. For example, GPT-4o can handle 128,000 tokens, Claude manages 200,000, and Gemini boasts a whopping 1,000,000 tokens. Keep these numbers in mind when uploading documents or crafting prompts.
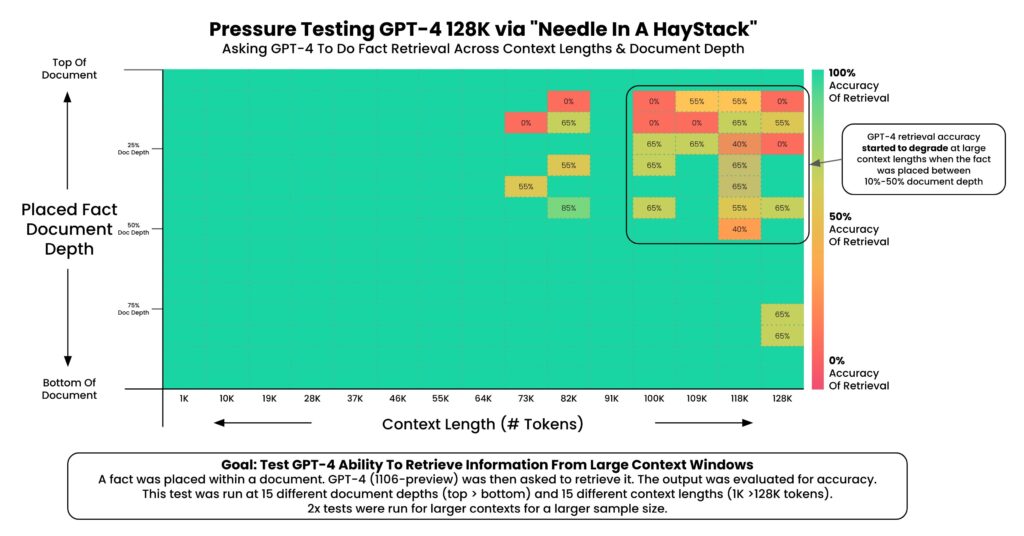
- Stay Within the Safe Zone: To minimize errors, aim to use only 25% of a model’s total context window. This creates a “manageable haystack,” making it easier for the AI to find your “needle” without hallucinating.1
- Be Strategic with Prompts: Include only the most relevant information and instructions. Overloading the AI with excessive details can muddy its understanding and lead to less reliable outcomes.

A context window is like an AI model’s short-term memory, defining how much information it can process at once. This table compares the token limits of three popular models as of 2024—GPT-4o, Claude, and Gemini—and converts these limits into approximate word counts and page equivalents (assuming 250 words per page). Tokens are the building blocks of text for AI, where 1 token is roughly 0.75 words. The “Safe” column highlights the recommended 25% PAGE usage limit to reduce errors like hallucinations and dropped context, making AI tools more reliable for researchers.
By understanding and respecting the context window, you can reduce errors and get more reliable results in your genealogical research. It’s a simple concept, but its impact on your work can be profound.
So, next time you sit down with an AI tool, remember: a well-managed context window isn’t just a technical detail—it’s your best ally in keeping the past clear and the present productive.
Next Week: “RAG (Retrieval Augmented Generation)”
One of the ways that AI builders are attempting to mitigate the limitations of a model’s context window is through a process called RAG (Retrieval Augmented Generation), a loathsome piece of jargon if there ever was one.
NOTES/Sources:
https://x.com/GregKamradt/status/1727018183608193393
- Why 25%? Several reasons: first, we have less access to the full context window than we might imagine; the context window includes both the INPUT and the OUTPUT to and from the model. Second, “needle in the haystack” research demonstrated that “fullness” of the context window impacted fact retrieval accuracy. Again, an example will clarify: imagine a model had a 100-page context window, and you upload a 95-page document for analysis; if you did that, the best you could expect (because the context window includes BOTH the INPUT and the OUTPUT) is five pages response with reasonable results (100-95=5), and then a quick decent into increasing errors and hallucinations, as more and more of your document “falls out” of the context window; by keeping the use of the context window well below 50%, say 33% or 25%, you reduce the hallucination rate and fact-retrieval error rate.
↩︎