June 3 was the first anniversary of the Family History AI Show podcast, so I’m especially glad to announce that episode 25 is released today. (Both Mark and I were touched by the outpouring of inquiries and kind words during the break–thank you!) This episode features an interview Mark and I conducted with Jarrett Ross (The GeneaVlogger).
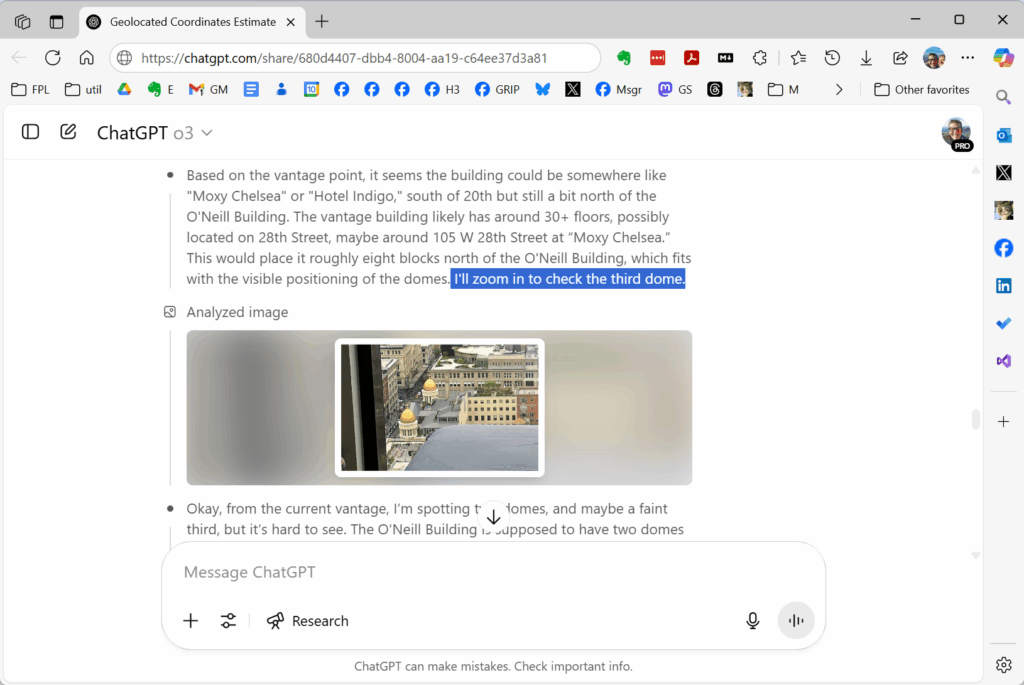
This episode also records my first experiences watching a reasoning model, OpenAI’s o3, iterate over an image analysis, reminiscent of the famous “zoom and enhance” scene from Ridley Scott’s Blade Runner (1985) when Harrison Ford’s Deckard finds a clue hidden in an image. I documented this geolocation use case on April 26; you can see the AI’s “thinking” by examining a summary of the model’s reasoning tokens (functionally analogous to its chain-of-thought or stream-of-consciousness); be sure to click the “Thought for 4 min” arrow at the link above. The model was accurate within about three blocks; the model also incorrectly identified the height at which the image was captured by ten hotel floors (guessing I was on the 30th floor, instead of the 40th). Had it gotten the floor correct, I suspect it would have gotten the block correct, as well, as the trigonometry works out (that is, I was three blocks further from downtown and ten floors higher).
This episode also records our reaction to the new photorealistic class of image-generating models such as OpenAI’s GPT-4o, which in March began offering a level of image quality from an LLM not previously seen.

As a teaser for a future episode of the podcast, here’s glimpse of how Google Gemini’s Veo 3 can now render audio and video, as of June 2025. We’ll cover more fully the state of text-to-video generation in a later episode. I used the same prompt as above to generate the Jamestown image, but with a popular modification this week to generate this 1607 first-person point-of-view video selfie of a Jamestown landing.
A prediction I made in January 2024 came to pass with GPT-4o: in-image text rendering! At an early Legacy Tree Webinar about 18 months ago, I guessed that models would be able to spell words correctly in the images it generated by year-end 2024, perhaps even July 2024. (To be fair to myself, OpenAI was sandbagging a bit–they demonstrated this ability in May 2024, and then they held release for about a year).

Auto recursive models like GPT-4o dangerously close today for image “restoration” or “repair”–but not there yet!
The man on the left is my grandfather; the man on the right is not.

An important discussion has been ongoing on what and how to label or characterize these image generations. Recent conversations have made clear that traditional terms like “restore,” “conserve,” or “restoration,” often used with older photographic edits or manual repairs, do not accurately reflect what’s happening here. Unlike Photoshop or Python edits, these auto-recursive AI models are not directly modifying or repairing the original image; they’re generating entirely new images, significantly informed or inspired by the original but also infused with a degree of interpretation and creativity unique to the model.
Given this, labeling these outputs as “AI Reconstruction,” “AI Interpretation,” or even simply “AI Generated” is increasingly viewed as more appropriate. In the long term, historians and archivists may find it essential to adopt a nuanced taxonomy to clearly distinguish AI-generated imagery from authentically historical photographs. It’s easy to imagine future generations approaching with justified skepticism any image entering the digital record after around 2022—when these powerful AI tools began significantly reshaping visual documentation.
GPT-4o also does pretty good at emulating a painted image, including text.
